What Even Is an 'AI Engineer'? — 425 JDs and One Reader's Comment Later
May 9, 2026·10 min read
TL;DR
49% of Software Engineer JDs already mention AI/ML. After scanning 425 fresh AI Engineer JDs, the role splits in two: every posting requires LLM integration, but only 36% require agentic systems on top. The label is doing more work than the boundary deserves — and the market knows it (less than 5% of JDs disclose salary).
A reader left a comment on my AI-vs-ML Engineer breakdown last week that I couldn't stop thinking about:
"For over 50% of the market, 'AI Engineer' just means a backend engineer with an LLM API key."

It was a throwaway line. It was also doing more work than the entire 2,000-word post above it.
The reason it bothered me: I'd just published a comparison framing AI Engineer as a distinct role with a distinct salary band and a distinct skill stack. And here was a working engineer saying — quietly, in a comment — no, it's mostly just SWE who learned the OpenAI SDK.
So I went back to the source.
This week I pulled 1,101 fresh LinkedIn JDs in the US — 429 Software Engineer, 425 AI Engineer, 247 Machine Learning Engineer postings, all from the last 30 days. I wanted to know what "AI Engineer" actually means in the market that's currently hiring it.
The commenter was more right than wrong.
The 49% problem
Start with what's happening on the SWE side.
49% of Software Engineer JDs in the dataset mention AI/ML in some form. 41% explicitly require AI/ML competence. And the GenAI-specific signals — Claude Code, Codex, OpenCode, "LLM-powered features," "RAG-based systems" — aren't aspirational mentions from forward-looking companies anymore. They're showing up as baseline expectations across a meaningful share of SWE roles being posted right now.
In other words: half the SWE market is already hiring for AI/ML — and the GenAI-specific subset is doing what an AI Engineer does in their day-to-day. Which raises the obvious question.
If half of all SWE postings already ask for AI/ML, where exactly does the SWE role end and the AI Engineer role begin?
The answer in the JD data is uncomfortable for anyone who's bought a $5,000 course to make the jump.
What the AI Engineer JDs actually ask for
I read through 425 AI Engineer JDs and pulled out what employers explicitly require, what they assume as baseline, and what they ask candidates to add.
The pattern:
- 73% require
Python - 22% require
AWS - The most common ICP description in the JD bodies: "software developers transitioning into machine learning and AI model deployment, often with experience in programming and cloud infrastructure"
- The top three "skills to add" called out across the dataset: prompt engineering, LLM integration, GenAI techniques
If you read that list and squint, what you're looking at is a backend engineer's resume with three new bullet points on top.
That's not a takedown — it's the actual hiring profile. And it lines up with what 64% of the JDs in the dataset are asking for: someone who can call LLM APIs cleanly, build RAG endpoints, ship LLM-powered features, integrate generative AI into existing software products.
That work is harder than the framing makes it sound. Production LLM features carry their own difficulty — eval pipelines, observability, prompt and cost management, retry and fallback chains, latency budgets. Calling an LLM is the entry. The engineering around it is what stays hard. The 64% job isn't trivial — it's just a different category of hard than the next 36%.
The other 36% is a different story. We'll get to it.
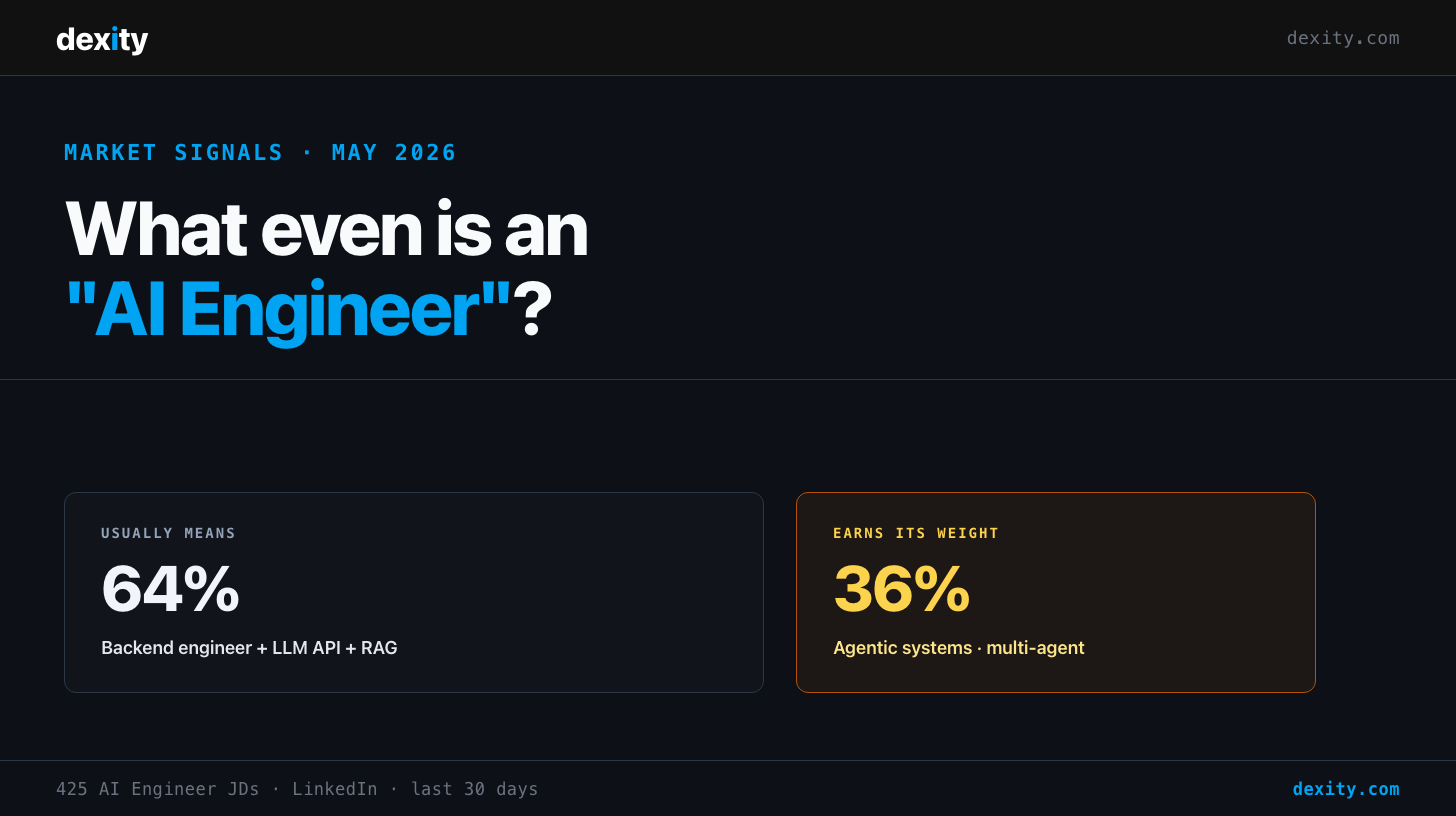
The 64/36 split
Pull out the agentic AI signal and the role visibly splits in two.
Important to be precise about how the data is structured: the 36% isn't a separate population. All 425 JDs require LLM/AI integration at the baseline. The 36% is an additive layer on top — postings asking for agentic depth in addition to the LLM-integration foundation. So it's not 64% vs 36% as opposing groups. It's: every AI Engineer role in this dataset needs LLM work; about a third want it WITH agentic systems on top.
That distinction matters for how you read the rest.
The 64% block — what the title usually means:
Backend engineer + LLM API + RAG. Python and AWS as foundation. Prompt engineering and LLM integration as the additive layer. The job is mostly: take a working software product and add an LLM-powered feature without breaking it. Hard, but a known shape of hard.
The 36% block — where the title earns extra weight: 155 of the 425 JDs explicitly require agentic AI work — autonomous agents, multi-agent orchestration, tool-using agents, agent-based architectures. This is systems work on top of the LLM-integration baseline. It involves designing how agents communicate, how they fail safely, how state flows across tool calls, how multi-step reasoning gets evaluated. There's no SDK that abstracts it away yet.
Both populations sit under the same job title. Both compete for the same career advice articles, the same bootcamps, the same LinkedIn feed.
They are not the same job, even though the boundary between them is one skill stack, not a clean wall.

Three signals the role hasn't solidified
If you're not sure which version of "AI Engineer" a posting is actually asking for, the JD itself usually won't tell you. Three signals will.
Signal 1 — Less than 5% of AI Engineer JDs disclose salary. For comparison, 72% of SWE JDs in the same dataset disclose salary. Markets disclose comp when the market has agreed on what the role is worth. When the disclosure rate is this low, what you're looking at is a category that hiring managers are still defining on the fly.
Signal 2 — The largest single hirer in the dataset is Prolific. $80/hour. Contract. 20 of the 425 JDs are from Prolific alone, all paying up to $80/hour, all contract. The next-largest hirer, Catalyst Labs, is also contract-flavored. Compare that to MLE, where General Motors leads with $170K–$300K full-time bands. When a category leans this heavily on contract and gig structures, the work is mostly project-shaped: ship a feature, evaluate a prompt, integrate a model. Real but bounded.
Signal 3 — Only 36% of AI Engineer JDs require agentic AI work. That's the sliver where the title earns its weight. The other 64% is API integration with extra steps — important work, valuable work, but not categorically different from "backend engineer who learned the OpenAI SDK."
What MLE looks like by contrast
To make the 64/36 split visible, contrast it with a role that has solidified — Machine Learning Engineer.
In the same scan, 247 MLE JDs:
| Signal | AI Engineer | MLE |
|---|---|---|
Python required |
73% | 82% |
AWS required |
22% | 34% |
Deep-learning frameworks (PyTorch, TensorFlow) |
minimal | 244 of 247 JDs |
| MLOps required | rare | 34% |
| Salary disclosure rate | <5% | 16% |
MLE hasn't been absorbed into the GenAI wave. The math, the training loops, the lifecycle management — these still gate on a different skill stack than "engineer who can call an LLM." It's the part of ML that didn't get commoditized when foundation models showed up.
That's why the salary band stretches to $300K at the high end. Markets pay for skill stacks that haven't been easily reproduced. They underprice categories that any senior backend engineer can plausibly add to their resume in three months.
What this means if you're upskilling
If you are a backend engineer already shipping LLM features at work — building a RAG endpoint, fine-tuning a prompt for a customer-support flow, integrating an LLM API into your product — you are already what 64% of the AI Engineer market is hiring for. You don't need a title change to confirm it. You need a portfolio that documents what you've shipped.
If you're earlier in your career — CS undergrad, recent bootcamp grad, career switcher from a non-coding role — this analysis is still useful as a market read, but the realistic next step is landing any SWE role first. The JD data confirms it: of the 425 AI Engineer postings, only ~4% are entry-level. This is a senior-tilted market. You can't shortcut the engineering muscle.
A note on math while we're here. Math is not absent from this role; it's table stakes. AI Engineer JDs don't list "linear algebra" the same way SWE JDs don't list "Big-O" — both assume you already have it at a foundational level. Where it surfaces: when retrieval scores look wrong, when an eval distribution doesn't match what users see, when fine-tuning won't converge. The point isn't to skip math. The point is to absorb it through the work, not to front-load six weeks of Khan Academy with no project to attach it to.
The mistake I see most often, working with people in the middle of this transition: paying $3,000–$5,000 for a course that teaches the OpenAI SDK, RAG basics, and a LangChain walkthrough. By the time the course ends, you have a certificate verifying skills you could have demonstrated by shipping one production feature.
The market isn't paying for the certificate. The market is paying for evidence that you can ship reliably under the constraints of a real codebase.
Where to invest your upskilling time
If you want to differentiate — to land in the 36% rather than the 64% — three real frontiers, in order of how legibly they signal "this person is past the SDK layer":
Agentic systems and multi-agent orchestration. Tool-using agents. Multi-agent workflows where state has to flow across calls. Failure modes — when does a tool call need a retry, when should an agent escalate, when does the system halt. This is where the JD market is starting to draw a real line, and the skill stack here doesn't reproduce in a weekend project. It takes shipping something agentic into production and watching it break.
Evals and inference-time engineering. Most LLM features in production today have no rigorous eval pipeline. Hiring managers know this and are increasingly explicit in JDs about wanting candidates who can build one. Quantitative eval frameworks, regression suites for prompts, benchmark harnesses. Closer to test-engineering than to ML research, and a real differentiator.
Fine-tuning and MLOps depth. Not because every AI Engineer needs to fine-tune a model, but because the engineers who can fine-tune are also the engineers who understand inference cost, latency, deployment pipelines, and observability. This is the skill stack that bridges into MLE territory if you ever want to make that jump.
The common thread: they involve owning a system end-to-end, not just calling an API. That's the part the 64% job mostly doesn't ask for. That's why the 36% job is what most working professionals should actually be optimizing toward.
Common mistakes engineers make on this transition
Chasing the title instead of the skill stack. "AI Engineer" means a different thing depending on which JD you're looking at. The skill stack is the durable signal. The title catches up later.
Buying generalist AI courses to reproduce skills you already have. If you're a backend engineer with three years of API integration experience, a $4,000 LLM-Engineering course teaching you how to call an API is selling you something you can do already. Audit the syllabus before paying — if it stops at RAG basics, it's not where the gap is.
Optimizing for "AI Engineer" pay numbers from inflated comp surveys. The actual disclosed salaries in the JD market are not the $200K+ figures you'll see in viral hiring infographics. The disclosure rate is 5%. The largest hirer is paying $80/hour contract. The pay band at the top of the market exists, but it's narrow, it's at the agentic-systems end, and it's gated on demonstrable systems work — not titles.
Treating MLE and AI Engineer as a slope when they're a fork. A SWE doesn't gradually become an MLE by writing more LLM features. The math, training loops, and MLOps are gating skills, not optional ones. If you want MLE comp, you need to commit to that path. If you want AI Engineer access, you've probably already qualified.
Where this leaves us
The label "AI Engineer" is doing too much work right now. It's covering a fat 64% of API-integration work that any competent backend engineer can ramp into in 3–6 months, and a smaller 36% of agentic-systems work that requires deeper investment.
The market hasn't agreed on which one the title points to. Until it does, the working professional's move is to ignore the label and pick the underlying skill stack.
If you're already shipping LLM features, you're already inside the 64%. Document it, ship one more thing publicly, move on.
If you want to be in the 36%, build something agentic and watch it break in production.
The label is doing too much work. The work underneath is what gets paid.
Source: LinkedIn JD scan — May 2026 (1,101 postings: 429 Software Engineer, 425 AI Engineer, 247 Machine Learning Engineer, US market, last 30 days). Cluster categorisation is LLM-assisted with mechanical re-counting on headline figures — treat percent shares as directional, not precise. · Dexity.com
Dexity Sprint
Ship Production Code with AI
Most senior engineers have tried Cursor or Claude Code and ended up with larger PRs, more review cycles, and hidden technical debt.
